
70-773 Dumps for Microsoft certification, Real Success Guaranteed with Updated 70-773 Braindumps. 100% PASS 70-773 Analyzing Big Data with Microsoft R (beta) exam Today!
Free 70-773 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You perform an analysis that produces the decision tree shown in the exhibit.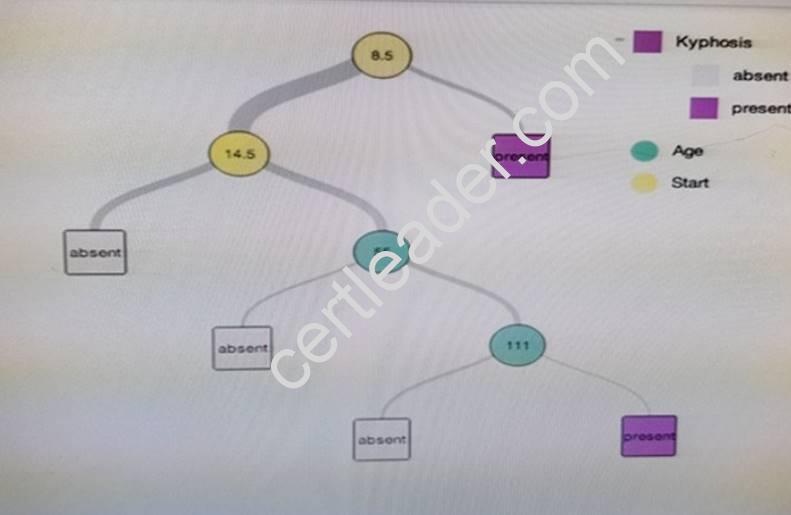
How many leaf nodes are there on the tree?
- A. 2
- B. 3
- C. 5
- D. 7
Answer: B
NEW QUESTION 2
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are developing a Microsoft R Open solution that will leverage the computing power of the database server for some of your datasets.
You are performing feature engineering and data preparation for the datasets. The following is a sample of the dataset.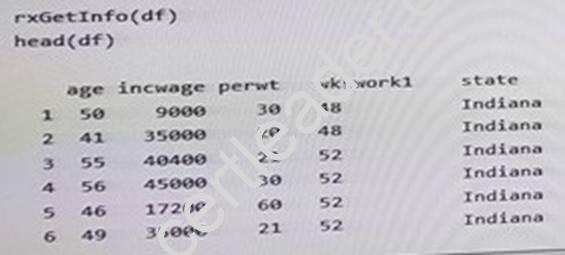
End of repeated scenario
You need to analyze the dataset without the missing values. The solution must not remove the missing values from the dataset.
Which R code segment should you use?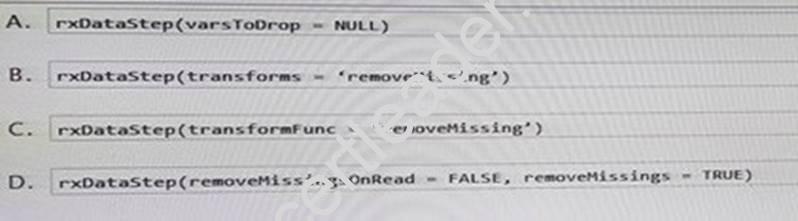
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 3
You need to run a larger data tree model by using rsDForest. The model must use cross validation.
Which rxDForest option should you use?
- A. maxSurrogate
- B. maxNumBins
- C. maxDepth
- D. maxCompete
- E. xVal
Answer: E
Explanation: https://docs.microsoft.com/en-us/r-server/r/how-to-revoscaler-decision-tree
NEW QUESTION 4
You need to build a model that looks at the probability of an outcome. You must regulate between L1 and L2.
Which classification method should you use?
- A. Two-Class Neural Network
- B. Two-Class Support Vector Machine
- C. Two-Class Decision Forest
- D. Two-Class Logistic Regression
Answer: A
NEW QUESTION 5
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are developing a Microsoft R Open solution that will leverage the computing power of the database server for some of your datasets.
You are performing feature engineering and data preparation for the datasets. The following is a sample of the dataset.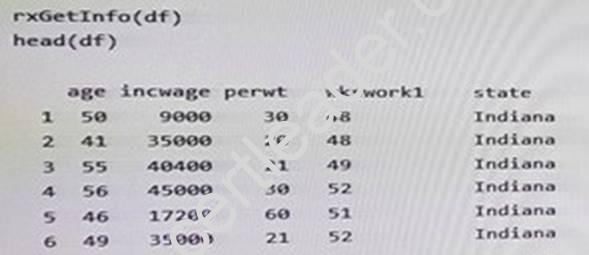
End of repeated scenario
You need to sort the data from the dataset sample and to remove duplicates by using wkswork1.
Which R code segment should you use? to answer, select the appropriate options in the
answer area.
Note: Each correct selection is worth one point.
Answer:
Explanation: 
NEW QUESTION 6
DRAG DROP
You need to set the compute context for three different target environments.
Which Statement should you use for each environment? To answer, drag the appropriate statements to the correct execution contexts. Each statement may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: 
NEW QUESTION 7
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are developing a Microsoft R Open solution that will leverage the computing power of the database server for some of your datasets.
You are performing feature engineering and data preparation for the datasets. The following is a sample of the dataset.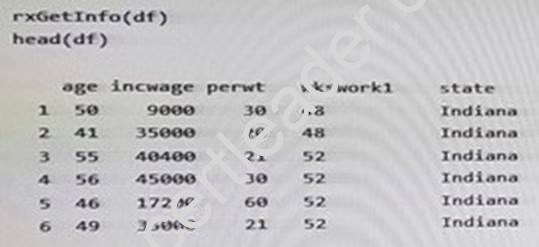
End of repeated scenario
You have the following R code.
Which function determines the variable?
- A. transformVars
- B. rxXdfToDataFrame
- C. createRandomSample
- D. transformFunc
Answer: A
NEW QUESTION 8
Note: This Question is part of a series of Questions that use the same or similar answer choices. An answer choice may be correct than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a dataset that contains the physical characteristics of people.
You need to visualize a relationship between height and weight for a subset of observations in the dataset.
What should you use?
- A. the Describe package
- B. the rxHistogram function
- C. the rxSummary function
- D. the rxQuantile function
- E. the rxCube function
- F. the summary function
- G. the rxCrossTabs function
- H. the ggplot2 package
Answer: E
NEW QUESTION 9
You are running a large logistic regression for 1,000 feature variables by using the logisticRegression0 function in the MicrosoftML package. All of the predictor variables are numeric.
Currently, you specify the input variables separately by using the following formula.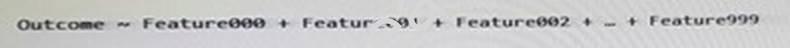
You discover that it takes 20 minutes to estimate each model.
You need to reduce the amount of time required to estimate each model without losing any information in the predictors.
What should you do?
- A. Use stepControl0 to perform stepwise regression to limit the number of variables that contribute to the model.
- B. Use selectFeatures0 to select the features that provide the most information about the outcome variable.
- C. Use princomp0 on the correlation matrix of Features, and then use only the first 100 principle components to reduce the number of input variables.
- D. Use concat0 to create a single array variable named Features, and then specify a newformula named Outcome - Features.
Answer: B
NEW QUESTION 10
Note: This question Is part of a series of questions that use the same or similar answer choice. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series.
Information and details provided In a question apply only to that question.
You need to generate a residual based on two columns. The solution must build a trend indicator.
Which function should you use?
- A. rxPredict
- B. rxLogit
- C. Summary
- D. rxLinMod
- E. rxTweedie
- F. stepAic
- G. rxTransform
- H. rxDataStep
Answer: C
NEW QUESTION 11
You are running a parallel function that uses the following R code segment. (Line numbers are included for reference only.)
You need to complete the R code. The solution must support chunking. Which function should insert at line 02?
- A. rxBTrees
- B. rxExec
- C. rxDForest
- D. rxDTree
Answer: C
NEW QUESTION 12
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You need to calculate a measure of central tendency and variability for the variables in a dataset that is grouped by using another categorical variable.
What should you use?
- A. the Describe package
- B. the rxHistogram function
- C. the rxSummary function
- D. the rxQuantile function
- E. the rxCube function
- F. the summary function
- G. the rxCrossTabs function
- H. the ggplot2 package
Answer: C
NEW QUESTION 13
Note: This Question is part of a series of Questions that use the same or similar answer choices. An answer choice may be correct than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a data source that is larger than memory.
You need to visualize the distribution of the values for a variable in the data source. What should you use?
- A. the Describe package
- B. the rxHistogram function
- C. the rxSummary function
- D. the rxQuantile function
- E. the rxCube function
- F. the summary function
- G. the rxCrossTabs function
- H. the ggplot2 package
Answer: B
NEW QUESTION 14
You have an Apache Hadoop Hive data warehouse. RevoScaleR is not installed. You need to sort the data according to the variables in the dataset.
What should you do?
- A. Connect to the database by using an ODBC connection, and then use the rxSort function.
- B. Create a table in the ORC file format.
- C. Connect to the database by using an ODBC connection, and then use the rxDataStep function.
- D. Execute a Hive query that sorts the data, and then reads the results.
Answer: D
NEW QUESTION 15
Note: This question is part of a series of Questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, whale others might not have a correct solution-After you answer a question in this section, you will NOT be able to return to it- As a result, these questions will not appear in the review screen.
You have a Microsoft SQL Server instance that has R Services (In-Database) installed. You need to monitor the R jobs that are sent to SQL Server.
Solution: You create an events trace configuration file and place the file in the same directory as the BXLServer process.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 16
You need to use the ScaleR distributed processing in an Apache Hadoop environment. Which data source should you use?
- A. Microsoft SQL Server database
- B. XDF data files
- C. ODBC data
- D. Teradata database
Answer: B
NEW QUESTION 17
Note: This question is part of a series of Questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, whale others might not have a correct solution-After you answer a question in this section, you will NOT be able to return to it- As a result, these questions will not appear in the review screen.
You use dplyrXdf. and you discover that after you exit the session, the output files that were created were deleted. You need to prevent the files from being deleted.
Solution: You use rxSetComputeContext with the local parameter before performing operations that save results.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 18
You have a dataset that has a character variable. You need to create a bag of counts of n-grams. Which function should you use?
- A. featurizeText0
- B. categoricalHash0
- C. concat0
- D. selcctFeatures0
- E. categorical0
Answer: A
Explanation: featurizeText: Produces a bag of counts of sequences of consecutive words, called n-grams, from a given
corpus of text. It offers language detection, tokenization, stopwords removing, text normalization and
feature generation.
Recommend!! Get the Full 70-773 dumps in VCE and PDF From 2passeasy, Welcome to Download: https://www.2passeasy.com/dumps/70-773/ (New 39 Q&As Version)