
Exam Code: 70-776 (Practice Exam Latest Test Questions VCE PDF)
Exam Name: Perform Big Data Engineering on Microsoft Cloud Services (beta)
Certification Provider: Microsoft
Free Today! Guaranteed Training- Pass 70-776 Exam.
NEW QUESTION 1
You are building a Microsoft Azure Stream Analytics job definition that includes inputs, queries, and outputs.
You need to create a job that automatically provides the highest level of parallelism to the compute instances.
What should you do?
- A. Configure event hubs and blobs to use the PartitionKey field as the partition ID.
- B. Set the partition key for the inputs, queries, and outputs to use the same partition folder
- C. Configure the queries to use uniform partition keys.
- D. Set the partition key for the inputs, queries, and outputs to use the same partition folder
- E. Configure the queries to use different partition keys.
- F. Define the number of input partitions to equal the number of output partitions.
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
NEW QUESTION 2
DRAG DROP
You need to create a dataset in Microsoft Azure Data Factory that meets the following requirements: How should you complete the JSON code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://github.com/aelij/azure-content/blob/master/articles/data-factory/data-factory-create-pipelines.md
NEW QUESTION 3
DRAG DROP
You use Microsoft Azure Stream Analytics to analyze data from an Azure event hub in real time and send the output to a table named Table1 in an Azure SQL database. Table1 has three columns named Date, EventID, and User.
You need to prevent duplicate data from being stored in the database.
How should you complete the statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 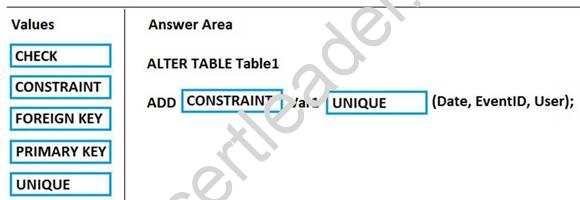
NEW QUESTION 4
You have a fact table named PowerUsage that has 10 billion rows. PowerUsage contains data about customer power usage during the last 12 months. The usage data is collected every minute. PowerUsage contains the columns configured as shown in the following table.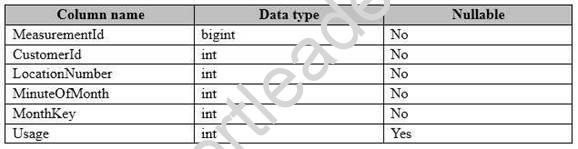
LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.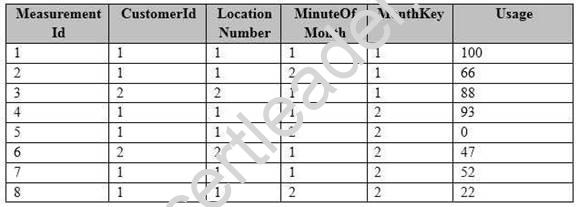
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month. What should you do?
- A. Implement partitioning by using the MonthKey colum
- B. Implement hash distribution by using the CustomerId column.
- C. Implement partitioning by using the CustomerId colum
- D. Implement hash distribution by using the MonthKey column.
- E. Implement partitioning by using the MonthKey colum
- F. Implement hash distribution by using the MeasurementId column.
- G. Implement partitioning by using the MinuteOfMonth colum
- H. Implement hash distribution by using the MeasurementId column.
Answer: C
NEW QUESTION 5
HOTSPOT
You use Microsoft Visual Studio to develop custom solutions for customers who use Microsoft Azure Data Lake Analytics.
You install the Data Lake Tools for Visual Studio.
You need to identify which tasks can be performed from Visual Studio and which tasks can be performed from the Azure portal.
What should you identify for each task? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.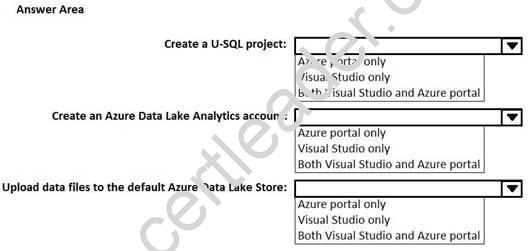
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 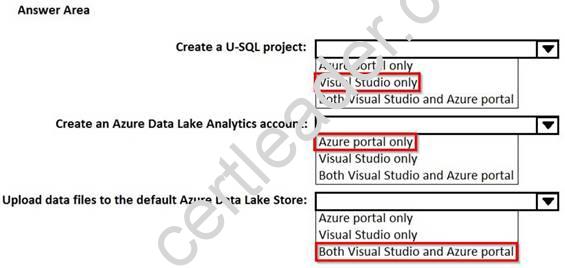
NEW QUESTION 6
You have an on-premises Microsoft SQL Server instance.
You plan to copy a table from the instance to a Microsoft Azure Storage account. You need to ensure that you can copy the table by using Azure Data Factory. Which service should you deploy?
- A. an on-premises data gateway
- B. Azure Application Gateway
- C. Data Management Gateway
- D. a virtual network gateway
Answer: C
NEW QUESTION 7
You ingest data into a Microsoft Azure event hub.
You need to export the data from the event hub to Azure Storage and to prepare the data for batch processing tasks in Azure Data Lake Analytics.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Run the Avro extractor from a U-SQL script.
- B. Create an Azure Storage account.
- C. Add a shared access policy.
- D. Enable Event Hubs Archive.
- E. Run the CSV extractor from a U-SQL script.
Answer: BD
NEW QUESTION 8
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
You need to define the schema of Table1 in AzureDF. What should you create?
- A. a gateway
- B. a linked service
- C. a dataset
- D. a pipeline
Answer: C
NEW QUESTION 9
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
- A. adataset
- B. a gateway
- C. a pipeline
- D. a linked service
Answer: A
NEW QUESTION 10
You have a Microsoft Azure Stream Analytics job.
You are debugging event information manually.
You need to view the event data that is being collected.
Which monitoring data should you view for the Stream Analytics job?
- A. query
- B. outputs
- C. scale
- D. inputs
Answer: D
NEW QUESTION 11
You plan to create several U-SQLjobs.
You need to store structured data and code that can be shared by the U-SQL jobs. What should you use?
- A. a U-SQL package
- B. a data-tier application
- C. Microsoft Azure Data Catalog
- D. Microsoft Azure Blob storage
Answer: C
NEW QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a clustered columnstore index.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 13
HOTSPOT
You are designing a fact table that has 100 million rows and 1,800 partitions. The partitions are defined based on a column named OrderDayKey. The fact table will contain:
Data from the last five years
A clustered columnstore index
A column named YearMonthKey that stores the year and the month
Multiple transformations will be performed on the fact table during the loading process. The fact table will be hash distributed on a column named OrderId.
You plan to load the data to a staging table and to perform transformations on the staging table. You will then load the data from the staging table to the final fact table.
You need to design a solution to load the data to the fact table. The solution must minimize how long it takes to perform the following tasks:
Load the staging table.
Transfer the data from the staging table to the fact table. Remove data that is older than five years.
Query the data in the fact table
How should you configure the tables? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.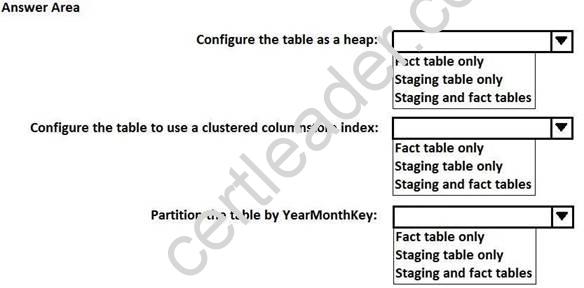
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 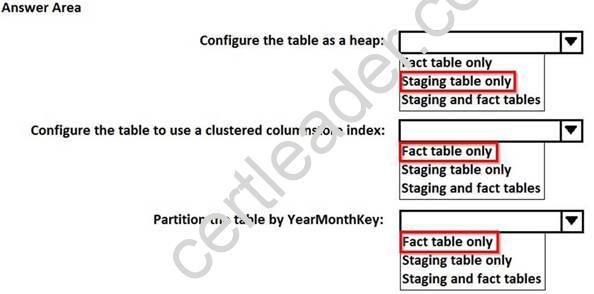
NEW QUESTION 14
HOTSPOT
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
How should you configure the storage to archive the source data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
NEW QUESTION 15
DRAG DROP
You have an on-premises Microsoft SQL Server instance named Instance1 that contains a database named DB1.
You have a Data Management Gateway named Gateway1.
You plan to create a linked service in Azure Data Factory for DB1.
You need to connect to DB1 by using standard SQL Server Authentication. You must use a username of User1 and a password of P@$$w0rd89.
How should you complete the JSON code? TO answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://github.com/uglide/azure-content/blob/master/articles/data-factory/data-factory-move-data-between-onprem-and-cloud.md
NEW QUESTION 16
You have a Microsoft Azure Data Lake Analytics service.
You have a CSV file that contains employee salaries.
You need to write a U-SQL query to load the file and to extract all the employees who earn salaries that are greater than $100,000. You must encapsulate the data for reuse.
What should you use?
- A. a table-valued function
- B. a view
- C. the extract command
- D. the output command
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-au/azure/data-lake-analytics/data-lake-analytics-u-sql-catalog
NEW QUESTION 17
You have a Microsoft Azure Data Lake Analytics service.
You need to write a U-SQL query to extract from a CSV file all the users who live in Boston, and then to save the results in a new CSV file.
Which U-SQL script should you use?



- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 18
You have a Microsoft Azure SQL data warehouse that has a fact table named FactOrder. FactOrder contains three columns named CustomerId, OrderId, and OrderDateKey. FactOrder is hash distributed on CustomerId. OrderId is the unique identifier for FactOrder. FactOrder contains 3 million rows.
Orders are distributed evenly among different customers from a table named dimCustomers that contains 2 million rows.
You often run queries that join FactOrder and dimCustomers by selecting and grouping by the OrderDateKey column.
You add 7 million rows to FactOrder. Most of the new records have a more recent OrderDateKey value than the previous records.
You need to reduce the execution time of queries that group on OrderDateKey and that join dimCustomers and FactOrder.
What should you do?
- A. Change the distribution for the FactOrder table to round robin.
- B. Update the statistics for the OrderDateKey column.
- C. Change the distribution for the FactOrder table to be based on OrderId.
- D. Change the distribution for the dimCustomers table to OrderDateKey.
Answer: B
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-statistics
NEW QUESTION 19
You have a Microsoft Azure SQL data warehouse. You have an Azure Data Lake Store that contains data from ORC, RC, Parquet, and delimited text files.
You need to load the data to the data warehouse in the least amount of time possible. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Use Microsoft SQL Server Integration Services (SSIS) to enumerate from the Data Lake Store by using a for loop.
- B. Use AzCopy to export the files from the Data Lake Store to Azure Blob storage.
- C. For each file in the loop, export the data to Parallel Data Warehouse by using a Microsoft SQL Server Native Client destination.
- D. Load the data by executing the CREATE TABLE AS SELECT statement.
- E. Use bcp to import the files.
- F. In the data warehouse, configure external tables and external file formats that correspond to the Data Lake Store.
Answer: DF
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 20
You have a file in a Microsoft Azure Data Lake Store that contains sales data. The file contains sales amounts by salesperson, by city, and by state.
You need to use U-SQL to calculate the percentage of sales that each city has for its respective state. Which code should you use?

- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 21
HOTSPOT
You have a Microsoft Azure Data Lake Analytics service.
You have a tab-delimited file named UserActivity.tsv that contains logs of user sessions. The file does not have a header row.
You need to create a table and to load the logs to the table. The solution must distribute the data by a column named SessionId.
How should you complete the U-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.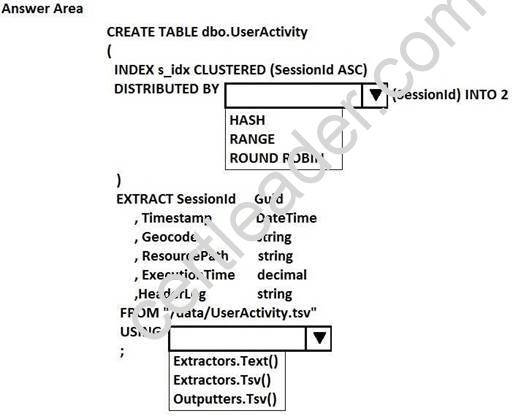
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://msdn.microsoft.com/en-us/library/mt706197.aspx
NEW QUESTION 22
......
P.S. Easily pass 70-776 Exam with 91 Q&As Dumpscollection Dumps & pdf Version, Welcome to Download the Newest Dumpscollection 70-776 Dumps: http://www.dumpscollection.net/dumps/70-776/ (91 New Questions)