
We provide which are the best for clearing CCA-500 test, and to get certified by Cloudera Cloudera Certified Administrator for Apache Hadoop (CCAH). The covers all the knowledge points of the real CCA-500 exam. Crack your Cloudera CCA-500 Exam with latest dumps, guaranteed!
Free CCA-500 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You are running a Hadoop cluster with a NameNode on host mynamenode, a secondary NameNode on host mysecondarynamenode and several DataNodes.
Which best describes how you determine when the last checkpoint happened?
- A. Execute hdfs namenode –report on the command line and look at the Last Checkpoint information
- B. Execute hdfs dfsadmin –saveNamespace on the command line which returns to you the last checkpoint value in fstime file
- C. Connect to the web UI of the Secondary NameNode (http://mysecondary:50090/) and look at the “Last Checkpoint” information
- D. Connect to the web UI of the NameNode (http://mynamenode:50070) and look at the “Last Checkpoint” information
Answer: C
Explanation: Reference:https://www.inkling.com/read/hadoop-definitive-guide-tom-white-3rd/chapter- 10/hdfs
NEW QUESTION 2
In CDH4 and later, which file contains a serialized form of all the directory and files inodes in the filesystem, giving the NameNode a persistent checkpoint of the filesystem metadata?
- A. fstime
- B. VERSION
- C. Fsimage_N (where N reflects transactions up to transaction ID N)
- D. Edits_N-M (where N-M transactions between transaction ID N and transaction ID N)
Answer: C
Explanation: Reference:http://mikepluta.com/tag/namenode/
NEW QUESTION 3
Your Hadoop cluster contains nodes in three racks. You have not configured the dfs.hosts property in the NameNode’s configuration file. What results?
- A. The NameNode will update the dfs.hosts property to include machines running the DataNode daemon on the next NameNode reboot or with the command dfsadmin–refreshNodes
- B. No new nodes can be added to the cluster until you specify them in the dfs.hosts file
- C. Any machine running the DataNode daemon can immediately join the cluster
- D. Presented with a blank dfs.hosts property, the NameNode will permit DataNodes specified in mapred.hosts to join the cluster
Answer: C
NEW QUESTION 4
Which two are features of Hadoop’s rack topology?(Choose two)
- A. Configuration of rack awareness is accomplished using a configuration fil
- B. You cannot use a rack topology script.
- C. Hadoop gives preference to intra-rack data transfer in order to conserve bandwidth
- D. Rack location is considered in the HDFS block placement policy
- E. HDFS is rack aware but MapReduce daemon are not
- F. Even for small clusters on a single rack, configuring rack awareness will improve performance
Answer: BC
NEW QUESTION 5
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)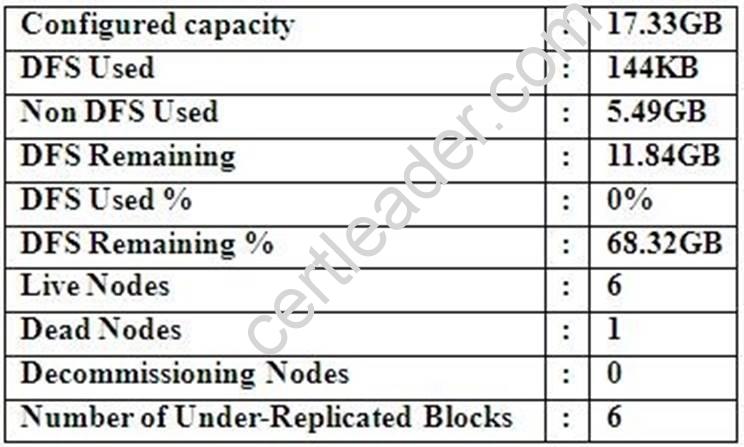
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?
- A. The DataNode JVM on one host is not active
- B. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS Used % equals 0%, you can’t be certain that your cluster has all the data you’ve written it.
- C. Your cluster has lost all HDFS data which had bocks stored on the dead DatNode
- D. The HDFS cluster is in safe mode
Answer: A
NEW QUESTION 6
On a cluster running CDH 5.0 or above, you use the hadoop fs –put command to write a 300MB file into a previously empty directory using an HDFS block size of 64 MB. Just after this command has finished writing 200 MB of this file, what would another use see when they look in directory?
- A. The directory will appear to be empty until the entire file write is completed on the cluster
- B. They will see the file with a ._COPYING_ extension on its nam
- C. If they view the file, they will see contents of the file up to the last completed block (as each 64MB block is written, that block becomes available)
- D. They will see the file with a ._COPYING_ extension on its nam
- E. If they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster
- F. They will see the file with its original nam
- G. If they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster
Answer: B
NEW QUESTION 7
Which scheduler would you deploy to ensure that your cluster allows short jobs to finish within a reasonable time without starting long-running jobs?
- A. Complexity Fair Scheduler (CFS)
- B. Capacity Scheduler
- C. Fair Scheduler
- D. FIFO Scheduler
Answer: C
Explanation: Reference:http://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html
NEW QUESTION 8
A user comes to you, complaining that when she attempts to submit a Hadoop job, it fails. There is a Directory in HDFS named /data/input. The Jar is named j.jar, and the driver class is named DriverClass.
She runs the command:
Hadoop jar j.jar DriverClass /data/input/data/output The error message returned includes the line:
PriviligedActionException as:training (auth:SIMPLE) cause:org.apache.hadoop.mapreduce.lib.input.invalidInputException:
Input path does not exist: file:/data/input What is the cause of the error?
- A. The user is not authorized to run the job on the cluster
- B. The output directory already exists
- C. The name of the driver has been spelled incorrectly on the command line
- D. The directory name is misspelled in HDFS
- E. The Hadoop configuration files on the client do not point to the cluster
Answer: A
NEW QUESTION 9
You are working on a project where you need to chain together MapReduce, Pig jobs. You also need the ability to use forks, decision points, and path joins. Which ecosystem project should you use to perform these actions?
- A. Oozie
- B. ZooKeeper
- C. HBase
- D. Sqoop
- E. HUE
Answer: A
NEW QUESTION 10
Which command does Hadoop offer to discover missing or corrupt HDFS data?
- A. Hdfs fs –du
- B. Hdfs fsck
- C. Dskchk
- D. The map-only checksum
- E. Hadoop does not provide any tools to discover missing or corrupt data; there is not need because three replicas are kept for each data block
Answer: B
Explanation: Reference:https://twiki.grid.iu.edu/bin/view/Storage/HadoopRecovery
NEW QUESTION 11
Which YARN daemon or service negotiations map and reduce Containers from the Scheduler, tracking their status and monitoring progress?
- A. NodeManager
- B. ApplicationMaster
- C. ApplicationManager
- D. ResourceManager
Answer: B
Explanation: Reference:http://www.devx.com/opensource/intro-to-apache-mapreduce-2-yarn.html(See resource manager)
NEW QUESTION 12
Your Hadoop cluster is configuring with HDFS and MapReduce version 2 (MRv2) on YARN. Can you configure a worker node to run a NodeManager daemon but not a DataNode daemon and still have a functional cluster?
- A. Ye
- B. The daemon will receive data from the NameNode to run Map tasks
- C. Ye
- D. The daemon will get data from another (non-local) DataNode to run Map tasks
- E. Ye
- F. The daemon will receive Map tasks only
- G. Ye
- H. The daemon will receive Reducer tasks only
Answer: B
NEW QUESTION 13
Assuming you’re not running HDFS Federation, what is the maximum number of NameNode daemons you should run on your cluster in order to avoid a “split-brain” scenario with your NameNode when running HDFS High Availability (HA) using Quorum- based storage?
- A. Two active NameNodes and two Standby NameNodes
- B. One active NameNode and one Standby NameNode
- C. Two active NameNodes and on Standby NameNode
- D. Unlimite
- E. HDFS High Availability (HA) is designed to overcome limitations on the number of NameNodes you can deploy
Answer: B
NEW QUESTION 14
You have installed a cluster HDFS and MapReduce version 2 (MRv2) on YARN. You have no dfs.hosts entry(ies) in your hdfs-site.xml configuration file. You configure a new worker node by setting fs.default.name in its configuration files to point to the NameNode on your cluster, and you start the DataNode daemon on that worker node. What do you have to do on the cluster to allow the worker node to join, and start sorting HDFS blocks?
- A. Without creating a dfs.hosts file or making any entries, run the commands hadoop.dfsadmin-refreshModes on the NameNode
- B. Restart the NameNode
- C. Creating a dfs.hosts file on the NameNode, add the worker Node’s name to it, then issue the command hadoop dfsadmin –refresh Nodes = on the Namenode
- D. Nothing; the worker node will automatically join the cluster when NameNode daemon is started
Answer: A
NEW QUESTION 15
You need to analyze 60,000,000 images stored in JPEG format, each of which is approximately 25 KB. Because you Hadoop cluster isn’t optimized for storing and processing many small files, you decide to do the following actions:
1. Group the individual images into a set of larger files
2. Use the set of larger files as input for a MapReduce job that processes them directly with python using Hadoop streaming.
Which data serialization system gives the flexibility to do this?
- A. CSV
- B. XML
- C. HTML
- D. Avro
- E. SequenceFiles
- F. JSON
Answer: E
Explanation: Sequence files are block-compressed and provide direct serialization and deserialization of several arbitrary data types (not just text). Sequence files can be generated as the output of other MapReduce tasks and are an efficient intermediate representation for data that is passing from one MapReduce job to anther.
NEW QUESTION 16
Which is the default scheduler in YARN?
- A. YARN doesn’t configure a default scheduler, you must first assign an appropriate scheduler class in yarn-site.xml
- B. Capacity Scheduler
- C. Fair Scheduler
- D. FIFO Scheduler
Answer: B
Explanation: Reference:http://hadoop.apache.org/docs/r2.4.1/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
NEW QUESTION 17
You have A 20 node Hadoop cluster, with 18 slave nodes and 2 master nodes running HDFS High Availability (HA). You want to minimize the chance of data loss in your cluster. What should you do?
- A. Add another master node to increase the number of nodes running the JournalNode which increases the number of machines available to HA to create a quorum
- B. Set an HDFS replication factor that provides data redundancy, protecting against node failure
- C. Run a Secondary NameNode on a different master from the NameNode in order to provide automatic recovery from a NameNode failure.
- D. Run the ResourceManager on a different master from the NameNode in order to load- share HDFS metadata processing
- E. Configure the cluster’s disk drives with an appropriate fault tolerant RAID level
Answer: D
NEW QUESTION 18
Your cluster is configured with HDFS and MapReduce version 2 (MRv2) on YARN. What is the result when you execute: hadoop jar SampleJar MyClass on a client machine?
- A. SampleJar.Jar is sent to the ApplicationMaster which allocates a container for SampleJar.Jar
- B. Sample.jar is placed in a temporary directory in HDFS
- C. SampleJar.jar is sent directly to the ResourceManager
- D. SampleJar.jar is serialized into an XML file which is submitted to the ApplicatoionMaster
Answer: A
100% Valid and Newest Version CCA-500 Questions & Answers shared by 2passeasy, Get Full Dumps HERE: https://www.2passeasy.com/dumps/CCA-500/ (New 60 Q&As)